- 分布式系统基础知识
- 数据库基础知识
- 了解GFS和MapReduce
- 了解Hadoop项目
- 了解Spark计算模型
- The Google File System 分布式文件系统,我们重点看第1、2章,第3章的第1、2节,第4章的2、3节,第5章的第1节[2h]
- 分布式键值存储 Dynamo 的实现原理 [2h]
- MapReduce: Simplified Data Processing on Large Clusters 大规模分布式计算系统,我们重点看前4章 [2h]
- 设计目标
- 普通硬件组成的大规模系统中,故障是常态
- 文件数量不是特别多 ( vs FB Haystack)
- 大文件,追加操作和流式读取为主
- 追求高吞吐而不是低延迟
- 架构
- 组件 - master, chunkserver, client
- 文件由固定长度的chunk组成,一般是64M
- 没有缓存
- master内存中维护所有的元数据, 和chunkserver通过心跳来通信
- 单点故障?
- 数据量
- 请求压力
- 数据如何保证安全?

- 主备份(primary)和租约机制(lease)
- 数据流和控制流
- 一致性如何保证?
- atomic record append
- 版本号与垃圾回收

- 分布式KV存储
- 无主架构
- 一致性哈希
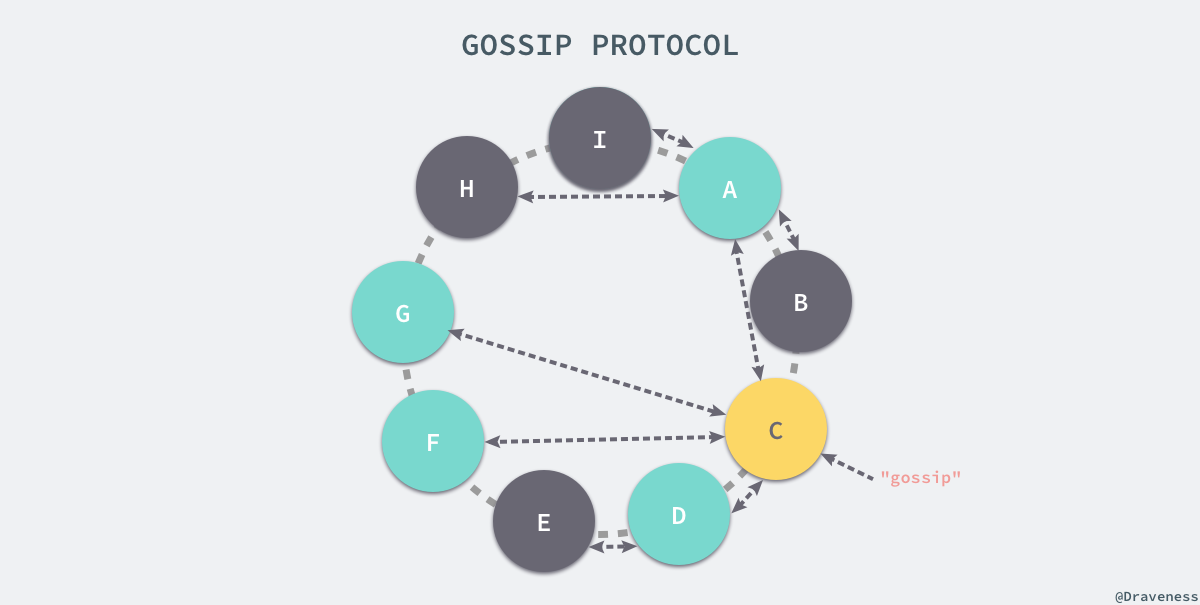
- Gossip协议
- Quorum一致性: R + W > N
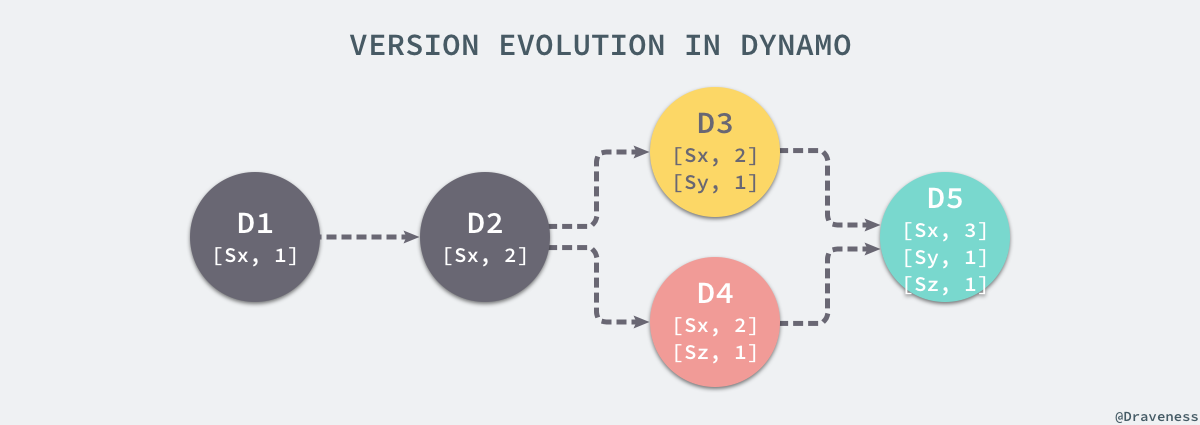
- 向量时钟
- 处理冲突数据
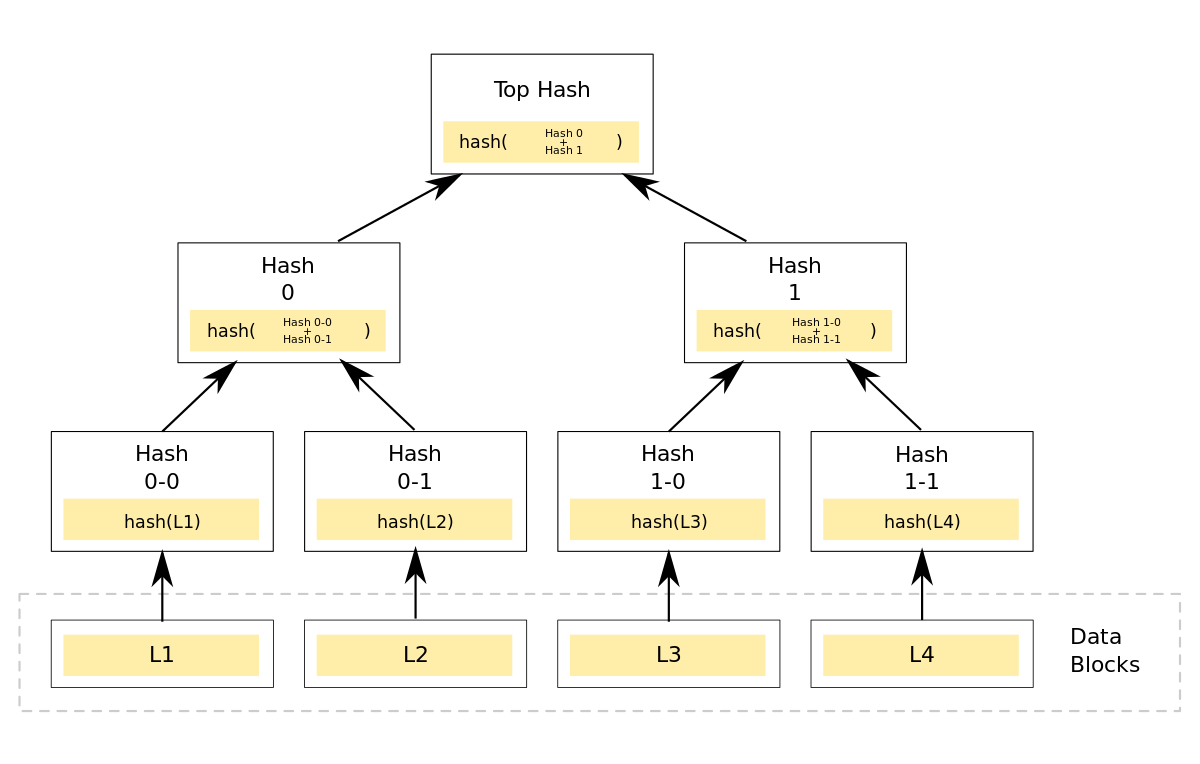
- 比较副本间的数据:Merkle Tree
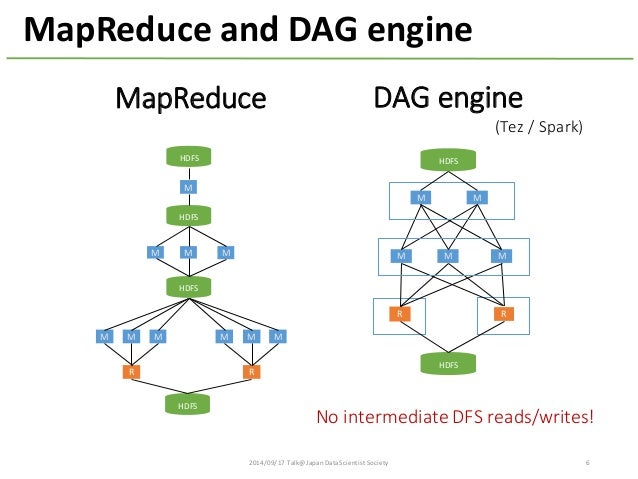
- MapReduce之前的分布式计算
- 使用Map操作和Reduce操作来定义计算

- 故障恢复
- 自定义Partition函数
- Combiner函数
- 实例
- Word Count
- Sort
- Page Rank
- 使用DAG来定义计算
- 中间数据不需要写磁盘
- Lazy执行
- 如何容错?
- 思考GFS提供了怎么样的一致性模型
- Bigtable: A Distributed Storage System for Structured Data Google的Bigtable数据库,HBase的原型
- Dynamo: Amazon’s Highly Available Key-value Store 亚马逊的Dynamo存储系统
- Finding a needle in Haystack: Facebook's photo storage Facebook的Haystack文件系统,用于存储海量小文件
- 知乎:分布式系统领域有哪些经典论文?