This repository contains the code and resources for building an edge device content moderation system using a fine-tuned Phi-3-mini-4k-instruct model. The project involves generating synthetic data using OpenAI's Meta-Llama-3.1-70B-Instruct-Turbo model, fine-tuning the Phi-3 model on the generated data, and deploying the model on a local device with a Streamlit application for real-time text categorization.
- Overview
- Step 1: Generation of Artificial Data
- Step 2: Fine-Tuning the Model
- Step 3: Deploying the Streamlit Application
- Screenshots
- Usage of AIML API
- Categories
- Requirements
- Installation
- Running the Application
- Conclusion
This project demonstrates the workflow of generating synthetic data, fine-tuning a machine learning model, and deploying it on an edge device using a Streamlit application. The entire workflow is designed to work without requiring internet access once the model is fine-tuned and deployed.
The first step involves generating synthetic data using the Meta-Llama-3.1-70B-Instruct-Turbo model from OpenAI. For each prompt-category pair, the code generates 100 samples, storing the responses in a Pandas DataFrame. This DataFrame is then saved as a CSV file named synthetic_data_500_samples_with_categoriesv2.1.csv.
The categories used for generating the synthetic data include:
- Positive
- Spam
- Neutral
- Misleading
- Inappropriate
The generated synthetic data is then used as the dataset for fine-tuning the Phi-3 model.
Below is a screenshot of the synthetic data generation process:
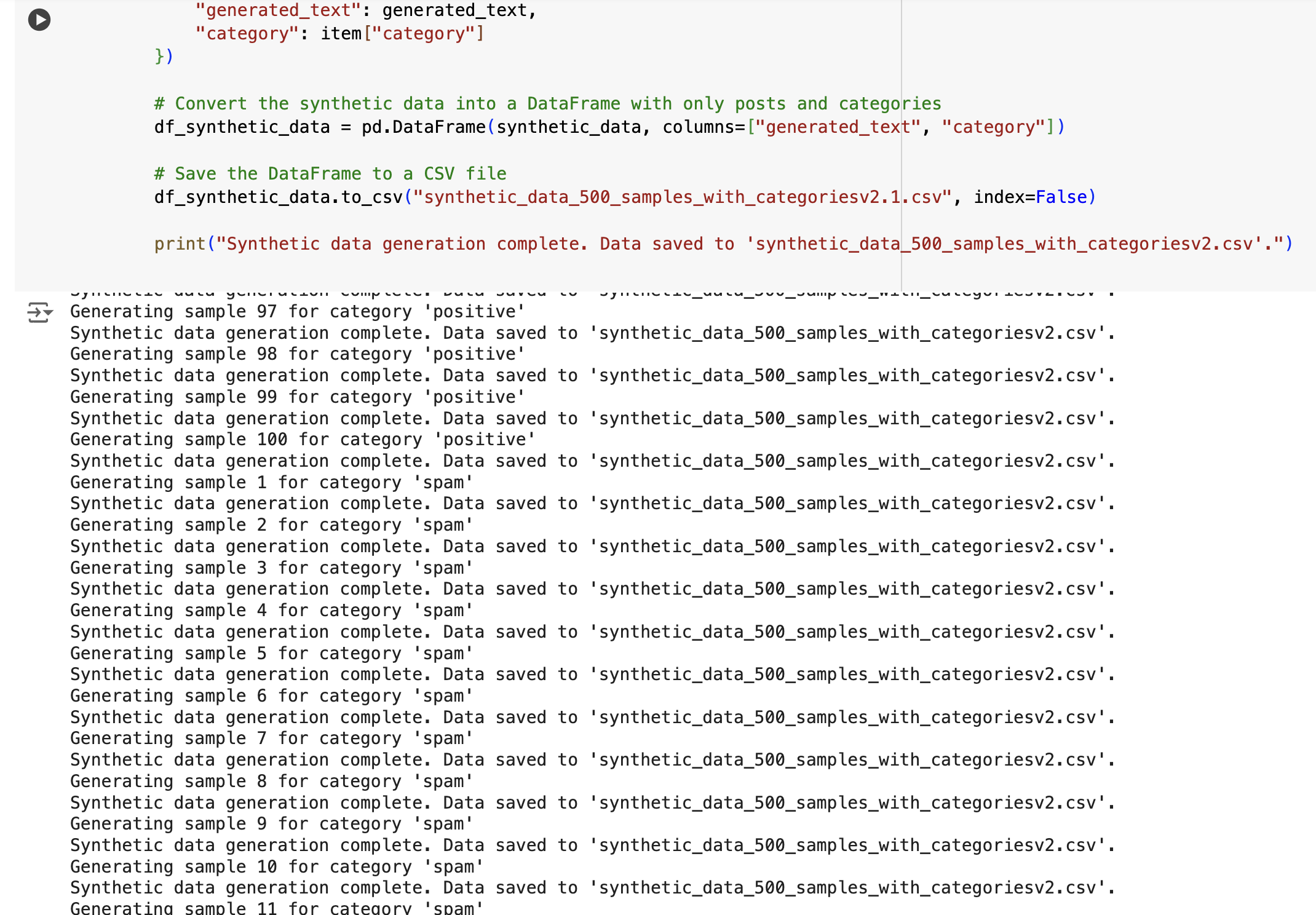
The artificial data generation process was performed on Google Colab, and you can find the notebook used for this process here.
The synthetic data is loaded into a Google Colab environment, where the Phi-3-mini-4k-instruct model is fine-tuned. The fine-tuning process adjusts the model's parameters to improve its ability to categorize text according to the predefined categories.
After fine-tuning, the model is saved and downloaded to the local machine for deployment. The saved model includes the LoRA adapters, which are stored in the trained-model directory.
The fine-tuning process was performed on Google Colab, and you can find the notebook used for this process here.
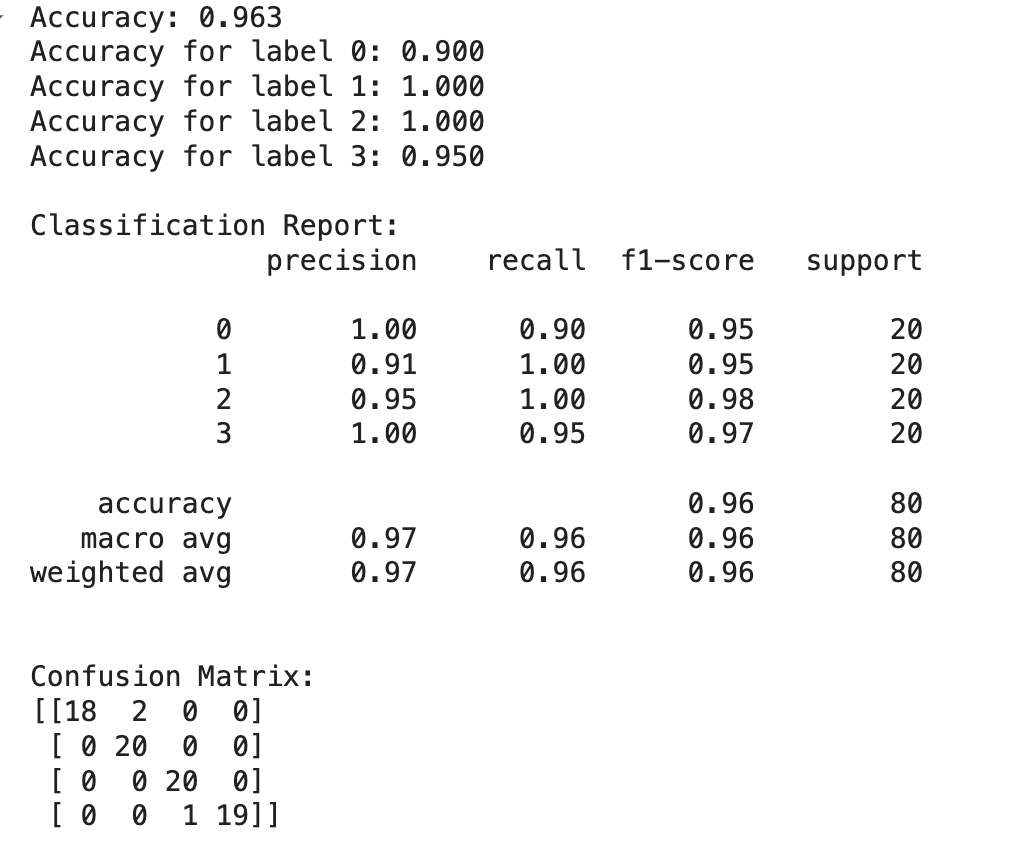
Before fine-tuning, the model's accuracy was evaluated on a validation dataset, yielding the following results:
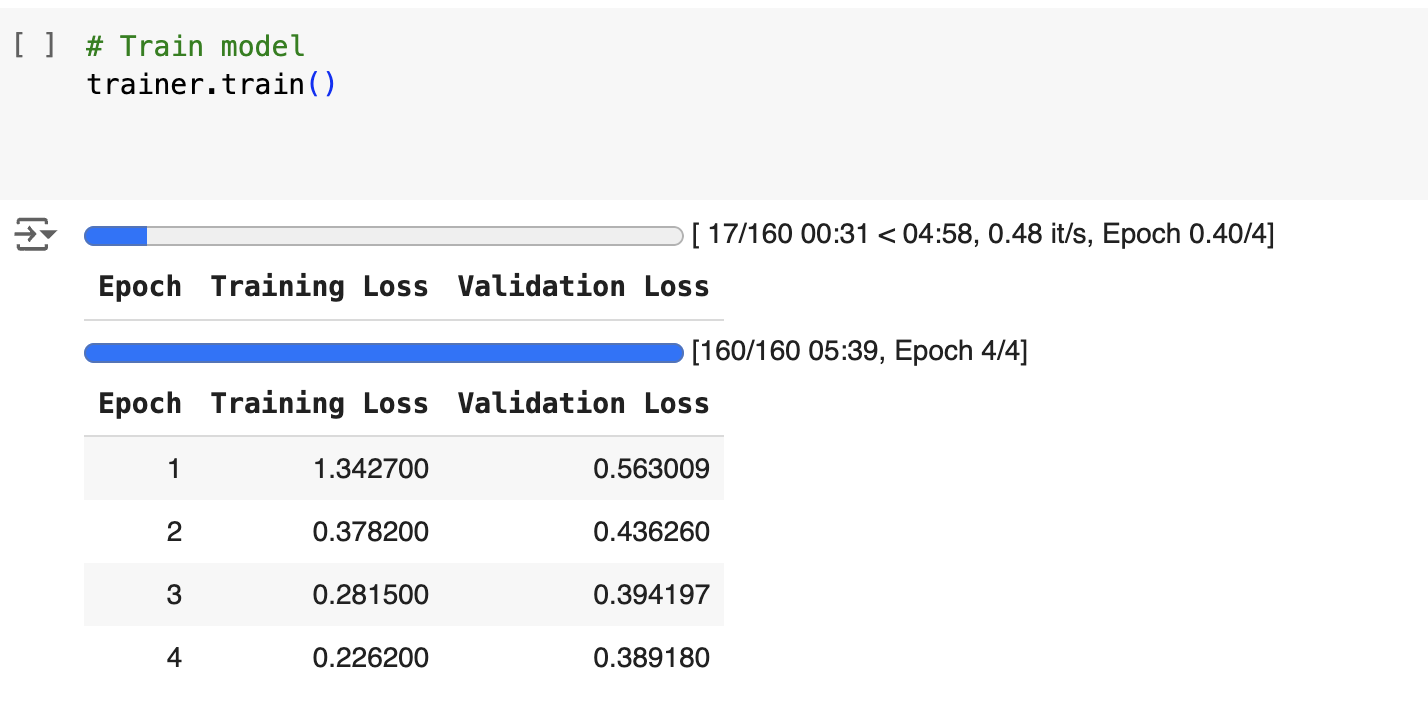
The model was fine-tuned over multiple epochs, with training and validation losses recorded as shown below:
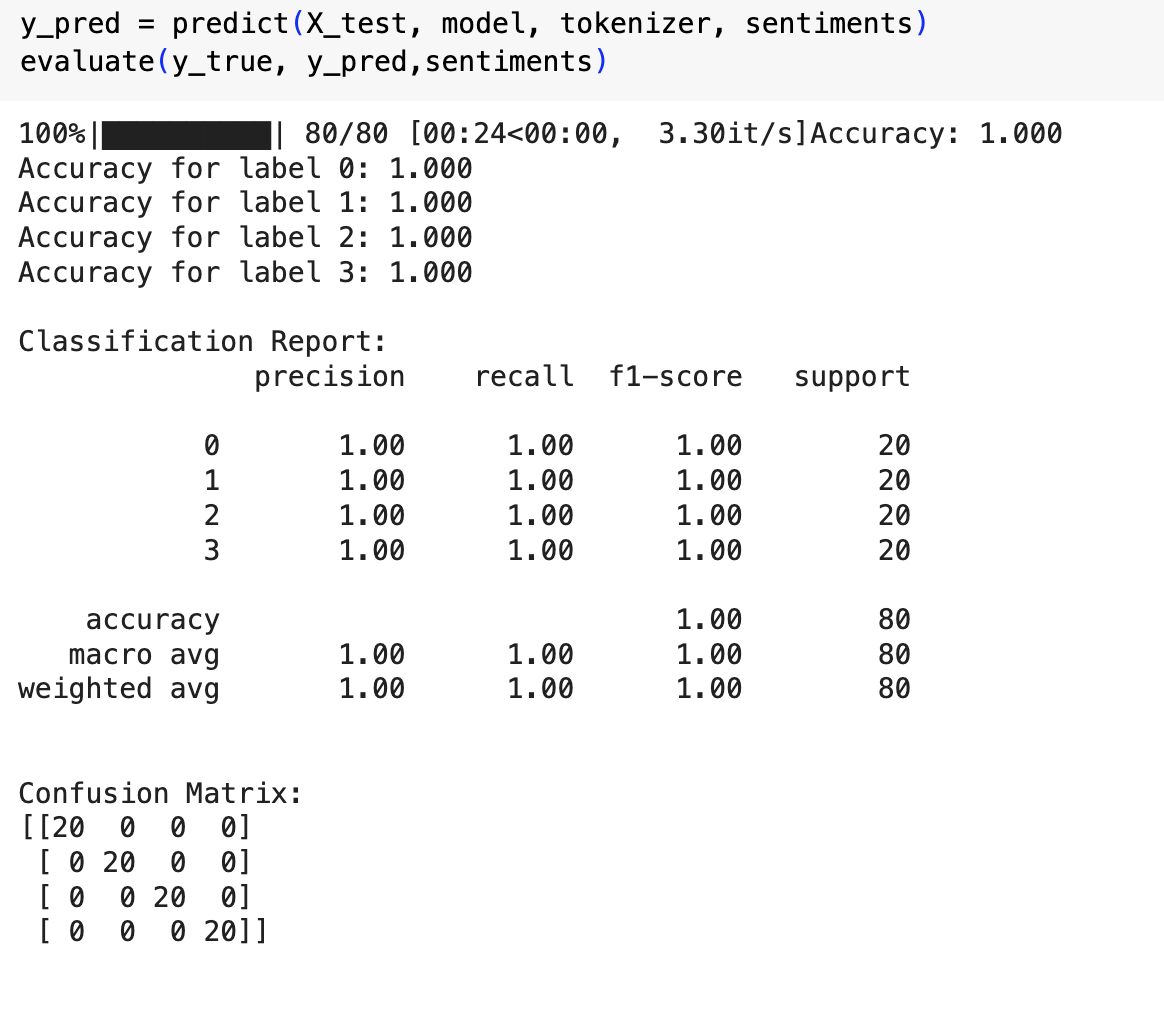
After fine-tuning, the model's accuracy improved significantly, as shown in the following evaluation:
The final step involves deploying a Streamlit application that runs locally without requiring internet access. The app uses the fine-tuned model to analyze user-input text and detect its category in real-time.
The following screenshots demonstrate the Streamlit application classifying various text inputs into categories. Note that the internet was off during all these tests, showcasing the model's capability to function fully offline.
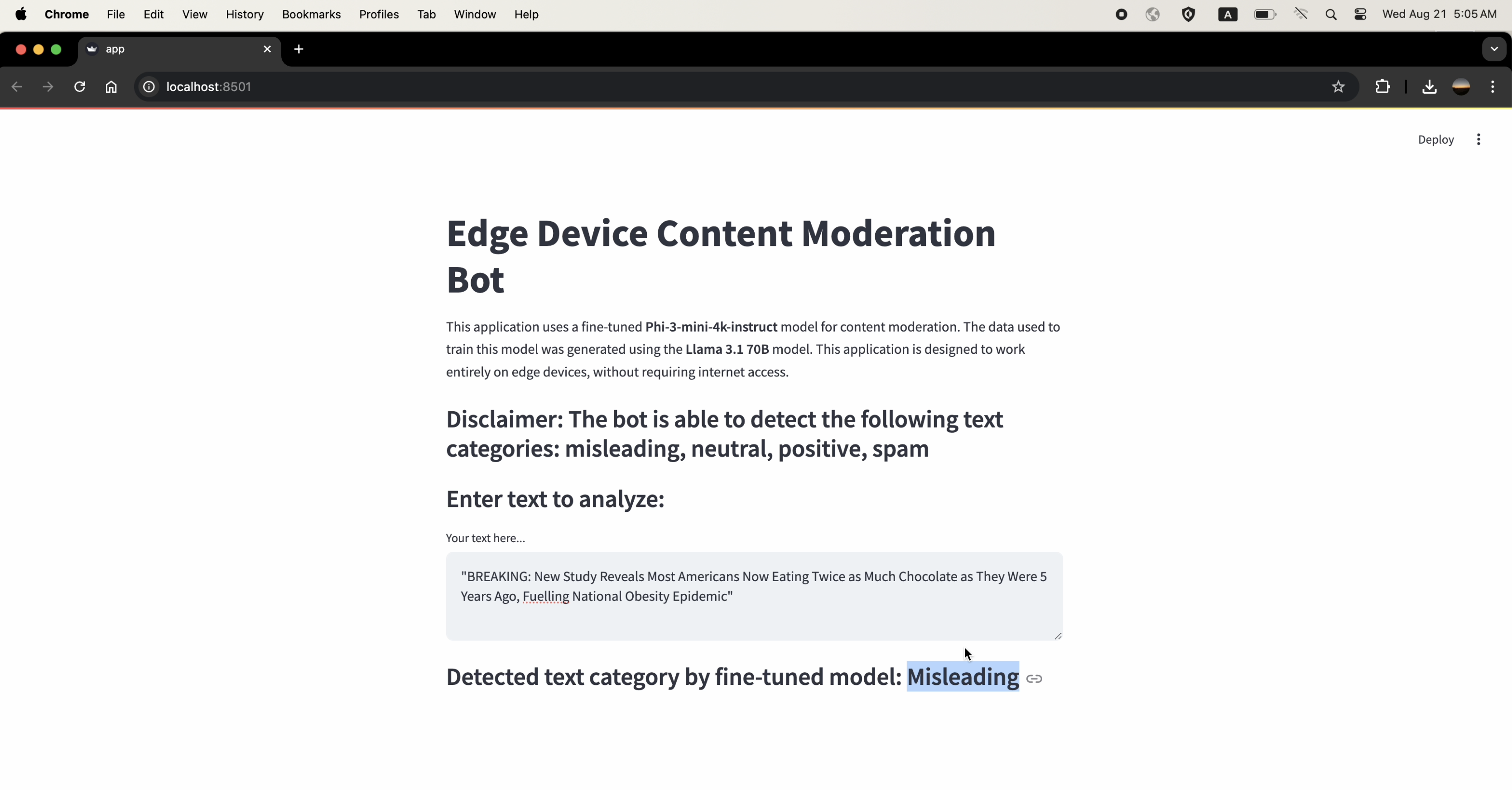
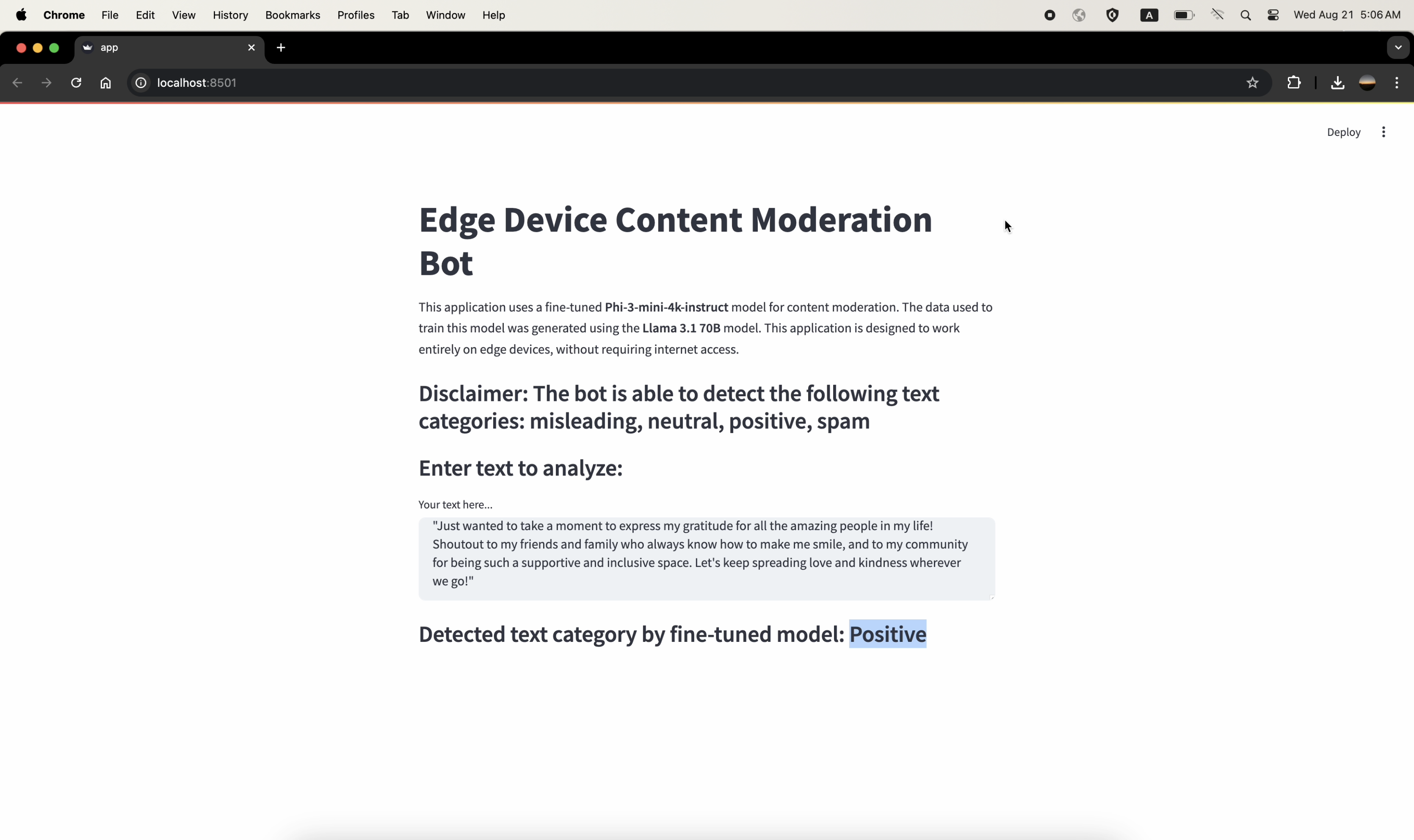
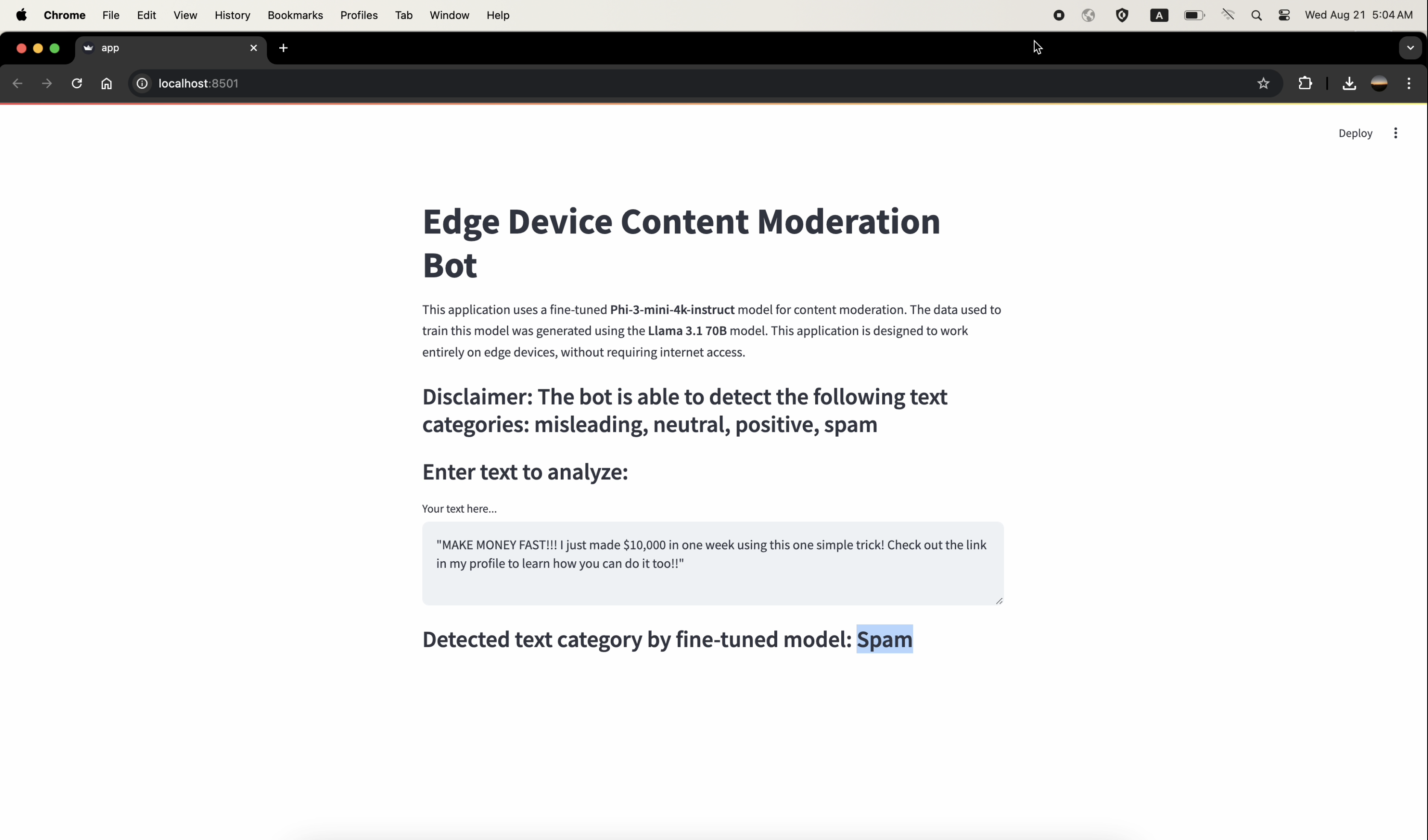
The AIML API is utilized in Step 1 to generate synthetic data using the Meta-Llama-3.1-70B-Instruct-Turbo model. The generated data is crucial for fine-tuning the Phi-3 model in Step 2.
The following categories are detected by the fine-tuned model:
- Positive
- Spam
- Neutral
- Misleading
- Inappropriate
- Python 3.7+
- Hugging Face Transformers
- Peft
- Pandas
- Streamlit
- Clone this repository:
git clone https://github.com/vikashkodati/nextedge-morpheus- Navigate to the project directory:
cd nextedge-morpheus- Install the required packages:
pip install -r requirements.txtIf you run into issues, then try the following:
- try lowering the python version
- use virtual python environments
- try changing the versions of the following towhatever is available on your laptop: tomli, torch==2.2.0, torchaudio==2.2.0, torchvision==0.17.0
To run the Streamlit application locally, use the following command:
cd streamlit_app
streamlit run app.pyThis will launch the web application on your local machine, allowing you to enter text and receive real-time category detection results.
Our product stands out from existing solutions in several important ways:
- Offline Capability: Unlike many AI models that rely on cloud-based services requiring constant internet connectivity, we've designed our product to run entirely on edge devices, such as smartphones, laptops, and IoT devices. This allows our solution to be highly accessible and functional even in environments with limited or no internet connectivity.
- Data Privacy: Since all processing happens locally on the device, we ensure that user data is not transmitted over the internet, enhancing privacy and security. This is especially important for applications that handle sensitive information.
- Specialized Fine-Tuning: We've fine-tuned our model specifically for content moderation tasks using synthetic data generated with the latest AI models like Meta-Llama-3.1-70B-Instruct-Turbo. This specialized fine-tuning makes our model more accurate and relevant for the task at hand, compared to generic models that might not perform as well in specific domains.
- Lightweight and Optimized for Edge Devices: We’ve carefully optimized our model to balance accuracy with computational efficiency on edge devices. This ensures smooth operation even in resource-constrained environments.
- Tailored Data: The training data we use isn’t just any dataset. We generate synthetic data to cover specific content moderation categories (like positive, spam, neutral, misleading, inappropriate), ensuring that our model is well-prepared to handle a wide range of real-world scenarios.
- Scalability and Flexibility: Our ability to generate synthetic data allows us to easily adapt to new categories or languages, offering flexibility that many existing solutions lack.
- Immediate Feedback: Our Streamlit-based application provides real-time feedback, categorizing text inputs instantly. This gives us a significant advantage in applications where immediate content moderation is critical, such as social media or messaging platforms.
- User-Friendly Interface: We’ve designed our Streamlit application with a simple and intuitive interface, making it easy for users to input text and receive category predictions without needing technical expertise.
- Cost-Effective: By running entirely on local devices without relying on external APIs or cloud services, we’ve made our solution more cost-effective in the long run, eliminating ongoing API usage fees.
- Robustness: Since our model operates independently of external services, it isn’t susceptible to downtime, API changes, or external dependencies, making it more reliable.
- Targeted Application: While many existing solutions offer general-purpose text classification, we’ve specifically tailored our product for content moderation, making it more effective in this domain. Our specialized focus allows for higher accuracy and better performance in detecting spam, misinformation, and other harmful content.
- Community-Driven: We’re positioning our product as open-source, allowing for community contributions and customizations. This leads to rapid improvements, greater transparency, and a solution that evolves according to user needs.
- Customizable: We provide the tools for users to fine-tune the model further or adapt the synthetic data generation process to suit their specific needs, offering a level of customization that many proprietary solutions don’t provide.
In summary, we differentiate our product through its offline capability, edge device optimization, tailored fine-tuning with synthetic data, real-time content moderation, independence from external APIs, and a specific focus on content moderation use cases. These features combine to create a powerful, flexible, and privacy-conscious solution that stands out in the crowded field of AI-powered text classification and content moderation tools.
This project showcases the complete workflow from generating synthetic data to fine-tuning a model and deploying it on an edge device. The Streamlit application offers a user-friendly interface for real-time text categorization, and the entire setup runs locally without requiring an internet connection.
[1] Fine-tune Phi-3 for sentiment analysis